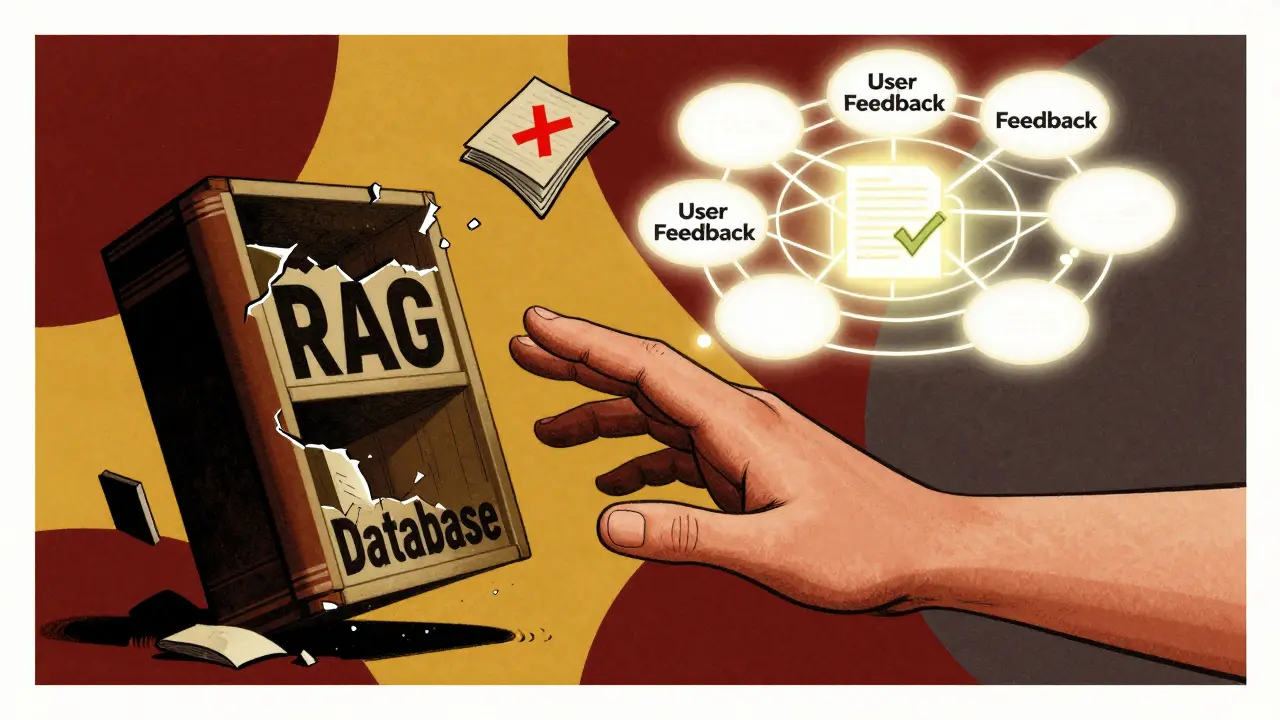
How Human Feedback Loops Make RAG Systems Smarter Over Time
Most RAG systems start strong but get worse over time. You feed them facts, they answer questions, and everything looks perfect-until it doesn’t. Users ask new things. The data changes. The answers start missing the mark. That’s not a bug. It’s a RAG flaw. The truth is, static retrieval doesn’t work in the real world. If you want your AI to stay accurate, you need to build in a way for it to learn from real people-not just algorithms.
Why RAG Gets Worse Before It Gets Better
RAG stands for Retrieval-Augmented Generation. It pulls relevant documents from a database and uses them to help an LLM generate answers. Sounds simple, right? But here’s the catch: the retrieval part is usually based on vector similarity. It finds documents that look similar to the question. But similarity doesn’t mean relevance. A document might have the right keywords but miss the context. Or it might be technically correct but outdated. Or it might be too long, too vague, or just not what the user actually needed. A 2024 analysis from Label Studio found that 67% of RAG failures happen because the system pulls the wrong documents. Not because the LLM is broken. Not because the prompt is bad. Because the retrieval engine doesn’t understand what the user really meant. And without feedback, it never learns.What Human Feedback Loops Actually Do
Human feedback loops fix this by turning users into teachers. Every time someone interacts with your RAG system, you give them a simple way to say: "This answer was wrong," or "Here’s what I needed instead." That feedback gets captured, analyzed, and fed back into the system-usually within seconds. The Pistis-RAG framework, developed by Crossing Minds and published in July 2024, shows how this works in practice. Instead of just asking, "Was this answer good?" it asks: "Which of these three retrieved documents would have made the answer better?" It looks at the whole list, not just one result. It learns patterns. It figures out that when users ask about "tax deductions for freelancers," they don’t want IRS.gov pages-they want real-world examples from accounting blogs. That’s the kind of insight no algorithm can guess on its own. This isn’t just theory. The same study showed that systems using human feedback improved accuracy by 6.06% on English benchmarks (MMLU) and 7.08% on Chinese ones (C-EVAL). That’s not a small tweak. That’s the difference between an AI that’s usable and one that’s trusted.How It Works: The Two Phases
A real feedback loop has two clear stages: alignment and querying. In the feedback alignment phase, the system collects human judgments-like which documents helped or hurt an answer-and uses them to retrain the ranking model. This isn’t just adding more data. It’s teaching the model what humans care about: not just keywords, but sequencing, depth, and clarity. The Pistis-RAG model was trained on over 15,000 labeled examples from real user queries across MMLU and C-EVAL datasets. It learned that a 100-word summary from a trusted source beats a 500-word technical paper if the user just needs a quick answer. Then comes the online querying phase. Every new question goes through the updated model. The system now pulls documents that match not just the text, but the hidden pattern of what made past answers good. The result? Faster, more accurate responses-even for questions it’s never seen before. Google Cloud’s 2025 guide says real-time feedback must happen in under 200ms to avoid frustrating users. That means the whole loop-from user click to updated ranking-has to be lightning fast. Systems that can’t meet this standard lose the trust they just earned.
Why This Beats Automated Metrics Alone
You might think: "Why not just use automated metrics like Ragas or DeepEval?" They’re great for testing. But they’re blind spots in production. Automated tools measure things like "retrieval precision" or "answer coherence" based on predefined rules. But they can’t tell if an answer is misleading because it’s missing a key nuance. They can’t tell if a user asked about "how to fix a leaky faucet" and got a 10-page plumbing manual instead of a 3-step fix. Label Studio’s 2024 case studies showed that human feedback loops reduce false positives-cases where automated tools think an answer is wrong when it’s actually fine-by 42%. That’s huge. Too many automated systems overcorrect, making answers overly cautious or generic. Human feedback keeps the system sharp without making it timid.Where It Shines (And Where It Struggles)
Human feedback loops work best in fast-moving environments:- Customer support: Questions change daily. Feedback helps the system adapt to new slang, new products, new policies.
- E-commerce: Product descriptions update. User intent shifts. A feedback loop learns that "best budget laptop" means different things in January vs. November.
- Technical documentation: Engineers don’t want theory-they want working code. Feedback teaches the system to prioritize GitHub snippets over white papers.
Implementation Costs and Real-World Challenges
Yes, this works. But it’s not plug-and-play. Braintrust’s 2025 survey of 127 companies found that setting up a human feedback loop adds 35% more engineering effort than a standard RAG pipeline. The hardest parts? Processing feedback signals and aligning them with your metrics. Most teams get stuck here. They collect feedback but don’t know how to turn it into better retrievals. Getting started? You need three things:- A way to capture feedback: A simple "Was this helpful?" button isn’t enough. Ask: "Which document should have been included?" or "What’s missing from this answer?"
- A structured review process: Package each feedback entry with the original query, the answer, the retrieved documents, and any automated scores.
- A team that cares: Don’t rely on random users. Build "opinionated tiger teams"-small groups of real users (both technical and non-technical) who review feedback weekly. Google’s case study showed this cut implementation time by 47%.

Market Trends and What’s Coming Next
As of Q3 2025, 28% of enterprise RAG systems use human feedback loops. That might sound low, but it’s growing fast. Gartner predicts 75% will have them by 2027. The market is heating up. Crossing Minds, Label Studio, Confident AI, and Braintrust are leading the charge. Crossing Minds holds nearly 29% market share. Their Pistis-RAG framework is now the gold standard for feedback-driven RAG. Updates are coming fast:- Google Cloud integrated real-time feedback into Vertex AI in December 2025, cutting latency to under 150ms.
- Label Studio released automated feedback categorization in November 2025, reducing review time by 38%.
- Pistis-RAG 2.0, launching in Q2 2026, will support multimodal feedback-like letting users highlight text in a PDF or draw arrows on diagrams.
Big Risks Nobody Talks About
Human feedback isn’t magic. It can make things worse. Dr. Emily Zhang from Stanford warned in her June 2025 NeurIPS talk that unfiltered feedback can amplify bias. If most users are from one demographic, the system learns to favor their preferences-and ignores others. MIT’s September 2025 study found that unchecked feedback loops increased demographic bias by up to 22% in some cases. The fix? Structure your feedback. Use diverse reviewer panels. Audit feedback patterns monthly. Don’t just collect votes-ask: "Who gave this feedback? Why?"Final Thought: Feedback Is the New Training Data
RAG systems used to be trained once and forgotten. Now, the best ones are constantly learning. Human feedback loops turn every interaction into a lesson. They turn users into co-developers. They turn static databases into living knowledge systems. If you’re building a RAG system today and you’re not building a feedback loop into it, you’re building something that will break. Not tomorrow. Not next year. Soon. Because the world changes faster than your database.Start small. Test with a tiger team. Measure the difference. Then scale. Because the most accurate AI isn’t the one with the most data. It’s the one that listens.
What’s the difference between human feedback loops and RLHF?
RLHF (Reinforcement Learning with Human Feedback) is used to train LLMs themselves-like teaching a model to write more politely or avoid harmful content. Human feedback loops in RAG focus on improving retrieval: which documents to pull before the LLM even speaks. They’re complementary but solve different problems. RAG feedback improves context; RLHF improves tone.
Can I use feedback loops without hiring reviewers?
Yes-but it’s risky. Some systems use implicit feedback, like tracking how long users read an answer or if they click "more like this." But these signals are noisy. A user might stay on a page because they’re confused, not because it’s helpful. Explicit feedback-where users rate or correct answers-is far more reliable. If you can’t get reviewers, start with power users or customer support agents who already know the answers.
How often should I retrain the retrieval model?
Monthly is a good baseline. If your domain changes fast-like customer support or news-you might need weekly updates. The Pistis-RAG framework uses online learning, so it adjusts after every batch of feedback. But you need to monitor performance. If accuracy drops for two weeks in a row, it’s time to retrain.
Do I need to label every piece of feedback?
No. You don’t need to label everything. Start with high-impact queries: popular questions, high-stakes answers, or ones flagged as wrong. Use clustering to group similar feedback. If 10 people say the same thing, you don’t need 10 labels. One well-explained example can teach the model the pattern.
Is human feedback loop RAG only for big companies?
Not anymore. While early adopters were enterprises with 500+ employees, tools like Label Studio and Confident AI now offer low-code interfaces. A small team can set up a basic feedback loop in under two weeks. You don’t need a team of ML engineers-just someone who understands user needs and can organize reviews.








man i just wanted my ai to answer simple questions without overthinking
now it’s like every answer needs a thesis and a bibliography
why cant it just say "i dont know" instead of pulling 5 weird docs that make no sense
Oh. My. God. This is exactly why 90% of corporate AI projects fail-because nobody’s willing to admit that retrieval isn’t magic. Vector similarity? Please. It’s like using a GPS to find your friend’s house… by matching the color of their driveway. And don’t even get me started on "accuracy improvements"-6%? That’s not progress-that’s just the difference between "meh" and "barely functional." And yes, I’m calling out Label Studio. Their "feedback loop" is just a fancy way of saying "we paid interns to fix our broken algorithm."
Also-"tiger teams"? That’s not a strategy. That’s a buzzword bingo card. Real teams don’t need names-they need clear KPIs. And if you’re not tracking which users are giving feedback-stop. You’re just reinforcing bias. And yes, I’m talking to you, Google Cloud. Your "150ms latency" is meaningless if the answer is wrong. And it usually is.
Stop selling this as innovation. It’s damage control. And if you think you can skip reviewers? You’re not building AI-you’re building a time bomb. With a user manual written by a 14-year-old.
Human feedback loops aren’t a feature-they’re a confession. A confession that your RAG system is fundamentally broken. That your retrieval engine is a glorified autocomplete with delusions of grandeur. And now you want users to fix it? For free? With a "Was this helpful?" button? That’s not feedback-that’s emotional labor wrapped in a startup pitch.
And don’t get me started on "Pistis-RAG." It’s not a framework-it’s a cult. 15,000 labeled examples? Sounds like someone’s PhD thesis with a fancy logo. Meanwhile, real engineers are out here scraping Reddit threads to teach their bots what "budget laptop" actually means. Not because the data says so-because people say so. And no algorithm can capture that. Not yet. Maybe never.
This is actually one of the most thoughtful takes I’ve seen on RAG in a while. The key insight-that feedback turns users into co-developers-is spot on. Most teams treat AI like a black box you throw data at and hope for the best. But this? This is how systems grow up. Not with bigger models. Not with more compute. But with listening. And yes, it’s messy. It’s slow. It’s expensive. But it’s the only way to build something that lasts. Start small. One tiger team. One week. One real user question that changes everything. That’s all you need.
all this talk about feedback loops and tiger teams and 15k labeled examples
bro. just use gpt-4o. it knows what you mean. no feedback needed.
why are we still building systems that need babysitting?
I appreciate how this piece frames feedback not as a workaround but as a philosophical shift-from static knowledge to dynamic learning. We’ve been treating AI like a library catalog when it should be a living conversation. The real breakthrough here isn’t technical-it’s relational. The system isn’t just retrieving documents. It’s retrieving *intent*. And intent is shaped by context, tone, culture, and nuance. That’s why automated metrics fail-they reduce meaning to patterns. Human feedback restores the humanity.
But here’s the quiet truth: this only works if we stop pretending feedback is a feature we can bolt on. It’s a culture. You need psychological safety for users to correct you. You need humility from engineers to admit their models are wrong. And you need patience. Not every user will be helpful. Some will be angry. Some will be confused. Some will be brilliant. You have to welcome them all. And listen. Really listen.
Real talk: if you’re not capturing "Which document should’ve been included?" you’re wasting time. The "Was this helpful?" button is garbage. It tells you nothing. People click yes because they’re tired. They click no because they’re mad. Neither helps the model. But if you ask them to pick the right doc? That’s gold. One user, one click, one correction-that’s how you teach the system. Start there. Skip the jargon. Skip the tiger teams. Just ask. Then watch. Then fix. Repeat.
USA built the internet. USA built AI. And now we’re asking users to fix our broken systems? No. We don’t need feedback loops. We need better engineers. Better data. Better models. Stop outsourcing intelligence to random people on the internet. That’s not innovation-that’s laziness. And if you’re building a RAG system for healthcare and letting some guy in Ohio correct your medical answers? You’re not just reckless-you’re dangerous. Fix the code. Don’t crowdsource truth.