
Video Understanding with Generative AI: Captioning, Summaries, and Scene Analysis
At its core, Video Understanding is a branch of multimodal AI that transforms unstructured video data into structured, searchable information through computer vision and natural language processing . It isn't just about recognizing a face or a car; it's about understanding that a person is frustrated because they've been clicking the same button for thirty seconds without a response. This level of insight is what's driving the current gold rush in enterprise AI.
How Generative AI Actually "Sees" Video
You might wonder how a model designed for text can suddenly understand a movie file. It doesn't actually "watch" the video the way we do. Instead, the system uses a multimodal processing pipeline. First, it performs frame extraction, pulling a series of still images from the video. Then, it uses feature encoding to turn those images into mathematical representations. Finally, it analyzes the temporal relationships-basically, how the images change over time-to understand motion and cause-and-effect.
The efficiency of this process comes down to tokenization. In older models, processing a single frame was computationally expensive. However, newer systems like Gemini 3 is a generative model that uses variable sequence length tokenization to process video frames at a rate of 70 tokens per frame . This is a massive leap from previous versions that required 258 tokens per frame, meaning we can process longer videos faster and with less memory.
Captioning, Summarization, and Scene Analysis
Depending on what you need, video understanding usually falls into three main buckets. Each serves a different "job-to-be-done" for the user:
- Automated Captioning: This goes beyond simple speech-to-text. AI can now describe what is happening visually. For example, it can note "A technician is replacing a motherboard in a server rack" even if no one is speaking. Current benchmarks show object recognition accuracy between 85% and 92%.
- Intelligent Summaries: Instead of a full transcript, the AI identifies key events. Netflix, for instance, used customized implementations to cut their metadata creation time by 92%, automatically identifying the climax or key plot points of a scene.
- Deep Scene Analysis: This is where the AI identifies complex interactions. It can detect if a safety helmet is being worn on a construction site or if a customer's body language suggests anger during a retail interaction.
| Model | Primary Strength | Processing Speed | Max Video Length | Computational Cost |
|---|---|---|---|---|
| Gemini 2.5-flash | Efficiency & Scale | 3.2s per video sec | 20 seconds (standard) | Low |
| Sora 2 | Temporal Coherence | 2.8s per video sec | 60 seconds | High (+40%) |
| Kling 2.6 | Mandarin Specialization | Varies | Varies | Moderate |

Practical Implementation for Developers
If you're looking to build this into an app, you don't need to train your own model from scratch. Most developers use Vertex AI is Google's enterprise AI platform that provides API access to Gemini models for video analysis . To get started, you generally need a project with the API enabled and a basic handle on Python-which 87% of these implementations use.
One pro tip from the documentation: if your prompt includes a video, always place the video file before the text prompt. This helps the model establish the visual context before it reads your specific instructions. You'll likely be working with formats like MP4 or MPEG-PS, with a typical limit of 2GB per request. If you're analyzing fast-action footage-like a soccer game or a car race-don't rely on default settings. You'll need to increase the Frame Per Second (FPS) sampling rate, otherwise, the AI might miss the exact moment a goal is scored.
The Reality Check: Where AI Still Struggles
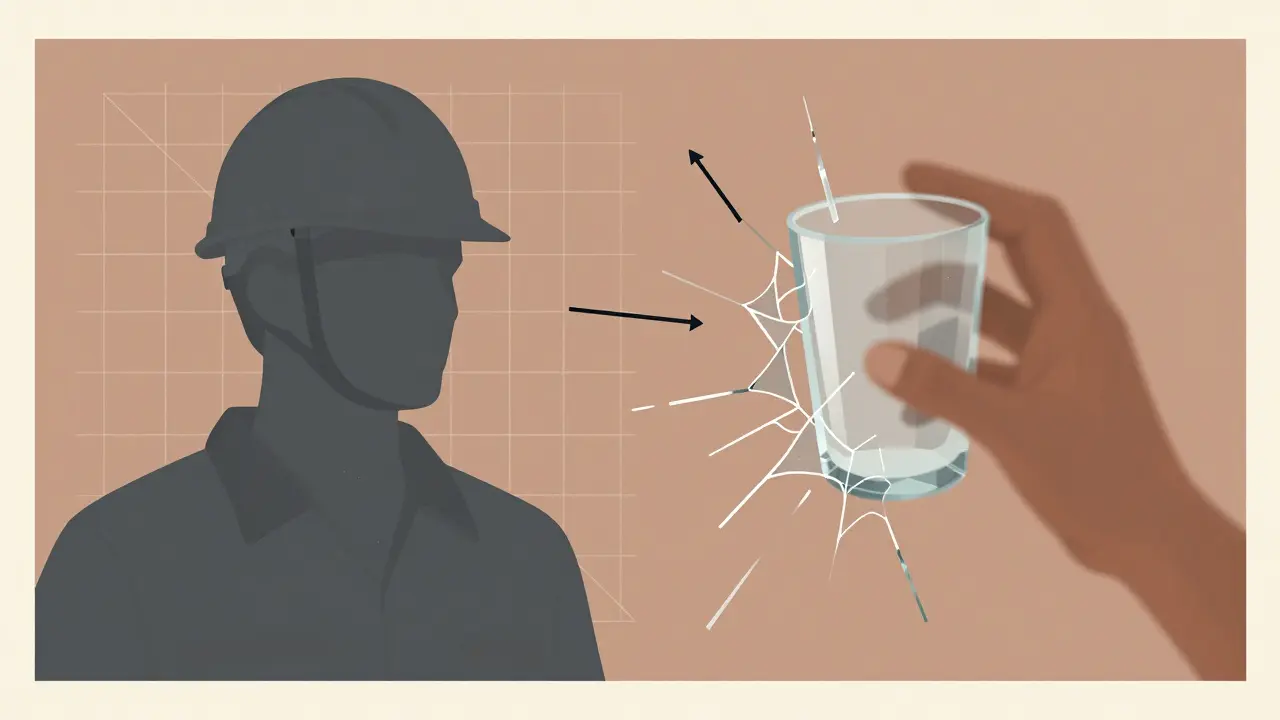
It's not all magic. There are some glaring gaps you should know about. First, there's the "causation vs. correlation" problem. As Professor Michael Chen from Stanford pointed out, models often struggle to understand why something happened. They might see a glass break and a hand moving, but they might not correctly conclude that the hand caused the break in every scenario.
Then there's the audio gap. While speech recognition is great, accuracy drops by 22% to 37% when the AI has to process non-speech sounds-like a siren or a dog barking. If your use case relies on these sounds for context, you're in for some errors. Additionally, complex videos with multiple people talking over each other can cause the accuracy of scene analysis to plummet by as much as 34%.
The Future of Multimodal Analysis
We are moving toward a world where real-time analysis is the norm. By late 2026, we expect to see systems capable of 30fps real-time analysis, meaning the AI can "narrate" a live feed with almost zero lag. However, this comes with a cost. Current generative video analysis requires about 4.7 times more energy than traditional, non-generative methods. As we scale, the industry will have to balance this thirst for power with the need for accuracy.
For those in the EU, keep an eye on GDPR. New rules now require explicit consent for biometric data processing in videos, which affects over 60% of current implementations. If you're building for a global audience, privacy isn't just a feature-it's a legal requirement.
What is the best model for long-form video analysis?
If you need high temporal coherence and longer clips, Sora 2 is generally superior, supporting up to 60 seconds of video. Gemini 2.5-flash is faster and cheaper but is better suited for shorter, snappier clips (up to 20 seconds) at scale.
How accurate is AI at describing video scenes?
For standard object recognition and scene description, accuracy sits between 85% and 92%. However, for high-stakes fields like medicine or law, it's not yet reliable enough, as these fields require 99.9% accuracy.
Can I use these models for non-English videos?
Yes, but performance varies. For example, Kling 2.6 is highly optimized for Mandarin, achieving nearly 90% accuracy, but its performance drops to around 72% for English content.
How do I reduce token consumption in Gemini?
The best way to manage costs is through strategic clipping and adjusting your frame sampling rate. Using Gemini 3's updated tokenization (70 tokens per frame) instead of older versions also significantly reduces overhead.
Does video understanding work in real-time?
Currently, most models process video at a rate of roughly 3 seconds of processing for every 1 second of video. Real-time 30fps analysis is on the roadmap for late 2026.
Next Steps and Troubleshooting
For the Developer: Start by enabling the Vertex AI API in your Google Cloud Console. If you notice the AI is missing key actions, check your sampling rate. A common mistake is using a low FPS for high-motion videos, which leads to "hallucinated" gaps in the narrative.
For the Business Owner: Before deploying a video analysis pipeline, conduct a manual audit of 5% of the AI's summaries. Because models can confuse correlation with causation, a human-in-the-loop is still essential for any business-critical reporting.
For the Creative: If you're using tools like Runway ML or Sora 2, experiment with the prompt structure. Remember that the AI understands physical simulations better than abstract emotional cues-be as concrete as possible with your visual descriptions.








This is an absolute goldmine of info! I love how you've broken down the multimodal pipeline into digestible chunks. For anyone diving into this, remember that the magic really happens when you tweak those sampling rates for high-energy footage-don't let your AI sleep on the job! It's such a vibrant time to be in dev, and seeing these efficiency gains in tokenization is just scrumptious for our cloud budgets.
wow luv the optimism here but like 3 secs per 1 sec of vid is basically real-time lol... just kidding, thats slow as molasses!! 🐌 can't wait for 2026 so we can finnaly automate away my whole job haha!
The notion that 85% accuracy is sufficient for general scene analysis is quite naive. In a professional environment, such a margin of error is simply unacceptable and reflects a lack of rigor in the current state of generative AI. One must wonder why these benchmarks are touted as achievements when they fail the most basic tests of precision.
I completely agree with the need for a human-in-the-loop approach!!! It is so vital to maintain a level of empathy and oversight when analyzing customer frustration... We must ensure that the AI's summary doesn't strip away the human element of the struggle!!!
the gdpr stuff is realy the most importent part here. if u dont get the consent right, the whole project is just a legal mess waitin to happen.
I'm really curious about how the audio gap affects the overall scene analysis, especially if the visual cues are ambiguous. It seems like the 34% drop in accuracy during overlapping speech is a huge hurdle for any real-world enterprise deployment. I wonder if combining this with a separate, specialized audio model could plug that hole, or if the multimodal approach is designed to handle that internally.