
Reproducibility in LLM Fine-Tuning: Seeds, Splits, and Logging Best Practices
You run a fine-tuning job on a Large Language Model. The validation loss drops nicely. You’re happy. You push the code to production, rerun it next week with the same dataset, and suddenly the model is hallucinating nonsense. What happened? Chances are, you didn’t control your random seeds, your data split shifted slightly, or you forgot to log the exact library versions. In machine learning, especially with Large Language Models that have billions of parameters, "good enough" isn’t reproducible. If you can’t reproduce it, you can’t trust it.
Reproducibility isn’t just an academic exercise for publishing papers. It’s the backbone of reliable AI engineering. When you’re fine-tuning models like Llama 3 or Mistral for enterprise tasks, you need to know exactly why a model performed well-or poorly. This article breaks down the three pillars of reproducibility: managing random seeds, handling data splits correctly, and implementing robust logging practices.
The Hidden Chaos of Randomness in Training
Randomness is everywhere in neural network training. It’s in how weights are initialized, how data is shuffled before each epoch, and even in dropout layers that randomly ignore neurons during training to prevent overfitting. If you don’t lock this randomness down, every time you hit "run," you get a different result. Sometimes better, sometimes worse. But never the same.
To fix this, you need to set random seeds across all relevant libraries. Python has its own random number generator. NumPy has another. PyTorch (or TensorFlow) has its own GPU-specific generators. Setting just one doesn’t help much.
Here is the standard approach for PyTorch-based fine-tuning:
- Python Seed: Set using
random.seed(42). - NumPy Seed: Set using
np.random.seed(42). - PyTorch CPU Seed: Set using
torch.manual_seed(42). - PyTorch GPU Seed: Set using
torch.cuda.manual_seed_all(42).
But wait, there’s more. Modern GPUs use non-deterministic algorithms for speed. Operations like matrix multiplication might take slightly different paths depending on hardware load, leading to tiny floating-point differences that compound over millions of steps. To force determinism, you often need to add these environment variables:
import os
os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
os.environ['PYTHONHASHSEED'] = '42'
torch.use_deterministic_algorithms(True)Note that enabling deterministic algorithms can slow down training significantly-sometimes by 10-20%. But if reproducibility is critical for your audit trail or scientific validation, this trade-off is worth it. Just remember: true bitwise reproducibility across different GPU architectures (e.g., NVIDIA A100 vs. H100) is still nearly impossible due to hardware-level differences. Aim for statistical reproducibility instead.
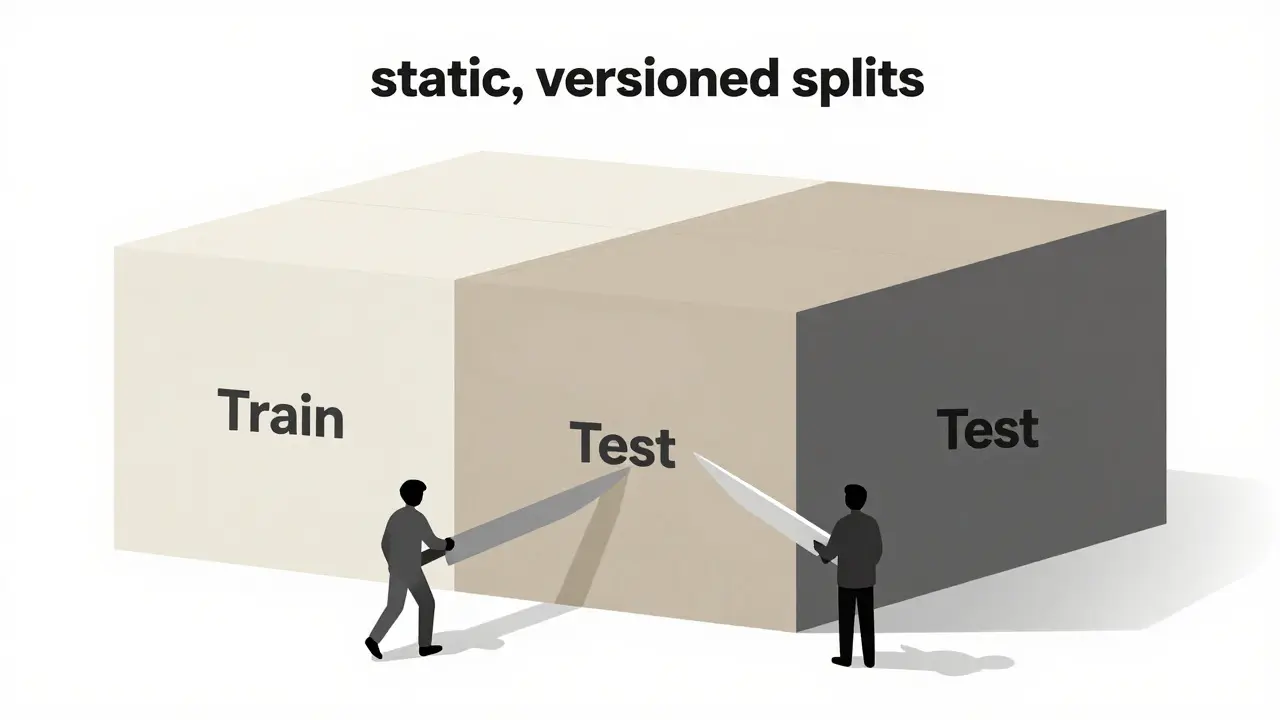
Data Splits: More Than Just 80/20
A common mistake is shuffling the entire dataset and slicing it into train/validation/test sets every time you run an experiment. If the shuffle isn’t seeded, your "test" set changes every run. You might accidentally leak test data into training, or worse, evaluate on a subset that’s easier than your real-world distribution.
For reproducible fine-tuning, you must create static, versioned splits. Here’s how to do it right:
- Define Your Split Strategy Early: Decide on your ratio. For most LLM tasks, 80% training, 10% validation, and 10% testing is a solid baseline. However, if your dataset is small (under 1,000 examples), consider stratified sampling to ensure class balance.
- Seed the Shuffle: Use a fixed seed when shuffling your DataFrame or list before splitting. This ensures that Example #1 always goes to the training set, not the test set.
- Save the Indices: Don’t just save the data. Save the indices or IDs of which samples belong to which split. This allows you to reload the exact same split later, even if you augment the original dataset.
- Check for Leakage: Ensure no duplicate entries exist across splits. If a customer support ticket appears in both train and test, your evaluation metrics will be inflated and misleading.
Consider using tools like DVC (Data Version Control) or simple JSON files to store your split mappings. For example, a file named splits_v1.json could contain lists of UUIDs for train, val, and test. This way, if you update your preprocessing pipeline, you can still evaluate against the same held-out test set.
| Pitfall | Impact on Reproducibility | Solution |
|---|---|---|
| Unseeded Shuffling | Different data in train/test every run | Use fixed random seed before splitting |
| Duplicate Records | Data leakage, inflated accuracy | Deduplicate dataset before splitting |
| Temporal Bias | Model learns future patterns | Split by date/time, not randomly |
| Class Imbalance | Poor generalization to rare cases | Use stratified sampling |
Logging: The Black Box Problem
You’ve set your seeds. You’ve locked your splits. Now you start training. After two hours, you see a loss curve. Is it good? Compared to what? Without detailed logging, you’re flying blind. Logging isn’t just about saving the final model weights. It’s about capturing the entire context of the experiment.
Effective logging should track three layers of information:
- Hyperparameters: Learning rate, batch size, number of epochs, warmup steps, weight decay. If you change the learning rate from 2e-5 to 5e-5, you need to know exactly when and why.
- Metrics: Track training loss, validation loss, and task-specific metrics (like F1 score or BLEU) at regular intervals. Don’t just log at the end. Log every step or every N steps so you can visualize convergence curves.
- Environment: Library versions (PyTorch, Transformers, Accelerate), CUDA version, GPU type, and even the commit hash of your code repository.
Manual logging via print statements is error-prone and hard to analyze. Instead, use dedicated experiment tracking platforms. Tools like Weights & Biases, MLflow, or Neptune.ai automatically capture these details. They allow you to compare runs side-by-side, filter by hyperparameters, and even roll back to previous model checkpoints.
For example, with Weights & Biases, you initialize a run at the start of your script:
import wandb
wandb.init(project="llm-finetuning", config={
"learning_rate": 2e-5,
"batch_size": 16,
"seed": 42
})Then, throughout training, you log metrics:
wandb.log({"train_loss": loss, "val_f1": f1_score})This creates a searchable history. Next month, when you wonder why Run #45 outperformed Run #44, you can check the logs. Maybe Run #45 had a slightly higher dropout rate. Without logging, that insight is lost forever.
Versioning Code, Data, and Models
Reproducibility extends beyond the training loop. You need to version everything. Think of your fine-tuning project as a software product. If you release v1.0 of an app, you want users to get the same experience regardless of when they download it. Same for AI models.
Start with code. Use Git. Commit your training scripts, configuration files, and preprocessing pipelines. Tag releases. Never modify a script mid-training without committing first.
Next, version your data. As mentioned earlier, DVC is excellent for this. It integrates with Git but handles large files efficiently. Each version of your dataset gets a unique hash. If you find a bug in your data cleaning logic, you can revert to the previous version without losing work.
Finally, version your models. Don’t just save model.pt. Save metadata alongside it. Include the training config, the data split used, and the evaluation results. Tools like Hugging Face Hub allow you to push model artifacts with associated cards that document their lineage. This makes it easy for teammates (or your future self) to understand what the model does and how it was built.
Parameter-Efficient Fine-Tuning and Reproducibility
Most modern fine-tuning uses Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA (Low-Rank Adaptation) or QLoRA. These methods freeze the base model and only train small adapter modules. This reduces memory usage and speeds up training.
Does PEFT affect reproducibility? Yes, but subtly. Since you’re only updating a fraction of parameters, the impact of random initialization in the adapters becomes more pronounced. Ensure you seed the initialization of LoRA weights specifically. In the Hugging Face Transformers library, you can pass a seed argument when initializing the LoRA configuration.
Also, note that quantization (used in QLoRA) introduces slight numerical instability. While 4-bit quantization saves massive amounts of VRAM, it may lead to minor variations in output compared to full-precision training. Document whether you used quantization, as it affects both performance and reproducibility.

Validating Reproducibility in Practice
How do you know if your setup is truly reproducible? Test it. Run the same experiment twice with identical seeds, splits, and configs. Compare the outputs.
If you’re using deterministic algorithms, the loss values should match exactly up to several decimal places. If you’re allowing non-deterministic GPU operations, the final model weights might differ slightly, but the evaluation metrics on the held-out test set should be statistically indistinguishable. A difference of less than 0.1% in F1 score is usually acceptable.
Create a validation script that automates this check. Load the saved model, run inference on a small benchmark set, and compare the outputs to a reference file. If they diverge significantly, investigate your pipeline. Check for unseeded operations, dynamic graph constructions, or external dependencies that might introduce variability.
Conclusion: Building Trust Through Transparency
Reproducibility in LLM fine-tuning isn’t optional. It’s the foundation of trustworthy AI. By controlling random seeds, locking data splits, and logging every detail of your experiments, you transform guesswork into science. You enable collaboration, debugging, and continuous improvement. Start small. Seed your runs. Log your metrics. Version your code. Over time, these habits will save you countless hours of frustration and build confidence in your models’ reliability.
Why is setting random seeds important in LLM fine-tuning?
Setting random seeds ensures that weight initialization, data shuffling, and dropout operations produce consistent results across runs. Without seeds, slight variations in randomness can lead to different model behaviors, making it impossible to verify improvements or debug issues reliably.
What is the best way to handle data splits for reproducibility?
Use a fixed random seed when shuffling your dataset before splitting. Save the indices or IDs of samples assigned to each split (train, validation, test) in a separate file. This allows you to reload the exact same split structure even if the underlying data changes or is preprocessed differently.
Which tools are recommended for experiment logging in fine-tuning?
Popular tools include Weights & Biases, MLflow, and Neptune.ai. These platforms automatically track hyperparameters, metrics, and environment details. They provide interfaces to compare runs, visualize loss curves, and store model artifacts with metadata for full transparency.
Does LoRA affect reproducibility compared to full fine-tuning?
Yes, LoRA requires careful seeding of the adapter weights since only a small subset of parameters is trained. Additionally, if using QLoRA (quantized LoRA), expect minor numerical variations due to quantization. Always document whether quantization was used, as it impacts both performance and reproducibility.
How can I validate that my fine-tuning process is reproducible?
Run the same experiment twice with identical configurations and seeds. Compare the training loss curves and final evaluation metrics. If using deterministic algorithms, losses should match closely. Otherwise, ensure evaluation metrics on the held-out test set remain statistically consistent (within ~0.1% variance).








The illusion of control in machine learning is the modern philosopher's stone, sought after by those who fear the chaos of existence. We set seeds not because we understand the universe, but because we crave a false sense of order in a deterministic void. To believe that a number like 42 grants you mastery over billions of parameters is a quaint delusion, a digital superstition for the tech-savvy masses. You lock your weights and pray to the silicon gods, ignoring the fundamental truth that entropy always wins in the end. It is tragic really, how much effort we pour into replicating results that were never truly ours to begin with.
I just started using DVC last week and it feels like magic compared to manually tracking splits. Do people actually still save split indices as JSON files or is that considered outdated now?
Look, if you can't reproduce your own damn model, you're not an engineer, you're a gambler. The article says it all but most of you are too lazy to implement proper logging. Stop making excuses about GPU non-determinism when the real issue is that you didn't bother to version your data pipeline. It's pathetic how many 'data scientists' treat their codebase like a black box and then act surprised when production fails. Get your house in order or get out of the industry.
Great point about the trade-off with deterministic algorithms. I've found that while CUBLAS_WORKSPACE_CONFIG helps, the slowdown is real on older architectures. For most enterprise tasks, statistical reproducibility is indeed the sweet spot. If you're doing safety-critical medical AI, sure, go full deterministic. But for chatbots? Just log everything thoroughly so you can trace back why a specific batch behaved oddly. Also, don't forget to seed the data loader workers in PyTorch, that's a common gotcha.
Oh my gosh! This is exactly what I needed!!! I spent three days debugging why my validation loss was jumping around like a kangaroo on caffeine!! Turns out I wasn't seeding the shuffle in my custom dataset class!! Thank you so much for this detailed breakdown!! I'm going to rewrite my entire training script tonight!!
the concept of reproducibility is just a construct we impose on nature to feel safe. randomness is the only truth. seeds are lies we tell ourselves.
only amateurs worry about bitwise reproducibility across different hardware. real engineers know that the underlying physics of floating point operations vary by chip architecture and temperature. if you think setting a seed makes your model portable from an A100 to an H100 without testing you are either naive or incompetent. american engineering standards have declined significantly since the golden age of computing when we actually cared about precision rather than speed.
lol u guys are so serious about this stuff. i just push to prod and hope for the best tbh. if it breaks i fix it later. also my code has typos everywhere but it runs so who cares?? determinism is for nerds lol.