Human-in-the-Loop Evaluation Pipelines for Large Language Models
When you ask a large language model to summarize a medical report, draft a legal email, or answer a sensitive customer question, how do you know it got it right? Automated scores can tell you if a response is grammatically clean-but they can’t tell you if it’s accurate, fair, or safe. That’s where human-in-the-loop (HITL) evaluation pipelines come in. They’re not just another tool. They’re the bridge between what AI can do quickly and what humans must ensure is right.
Why Automated Scores Alone Fail
You’ve probably seen metrics like BLEU, ROUGE, or METEOR. They measure word overlap between a model’s output and a reference answer. Sounds scientific, right? But here’s the problem: they don’t care about context. A response can be perfectly structured, use all the right keywords, and still be dangerously wrong.Imagine a model summarizing a patient’s history. It gets the dates and medications right-but accidentally drops a critical allergy. BLEU might give it a 9/10. A human? They’d spot the omission in seconds. That’s why companies like IBM and Thomson Reuters stopped relying on automated scores alone. They needed something that could catch what numbers miss.
LLMs themselves have become evaluation tools-called LLM-as-a-Judge. They can rate outputs on clarity, relevance, or safety. And they’re fast. One system can score 10,000 responses in an hour. But even these AI judges make mistakes. They’re trained on patterns, not lived experience. They don’t understand cultural nuance, legal gray areas, or emotional tone. When they’re unsure? They guess. And guessing at scale is a recipe for bad decisions.
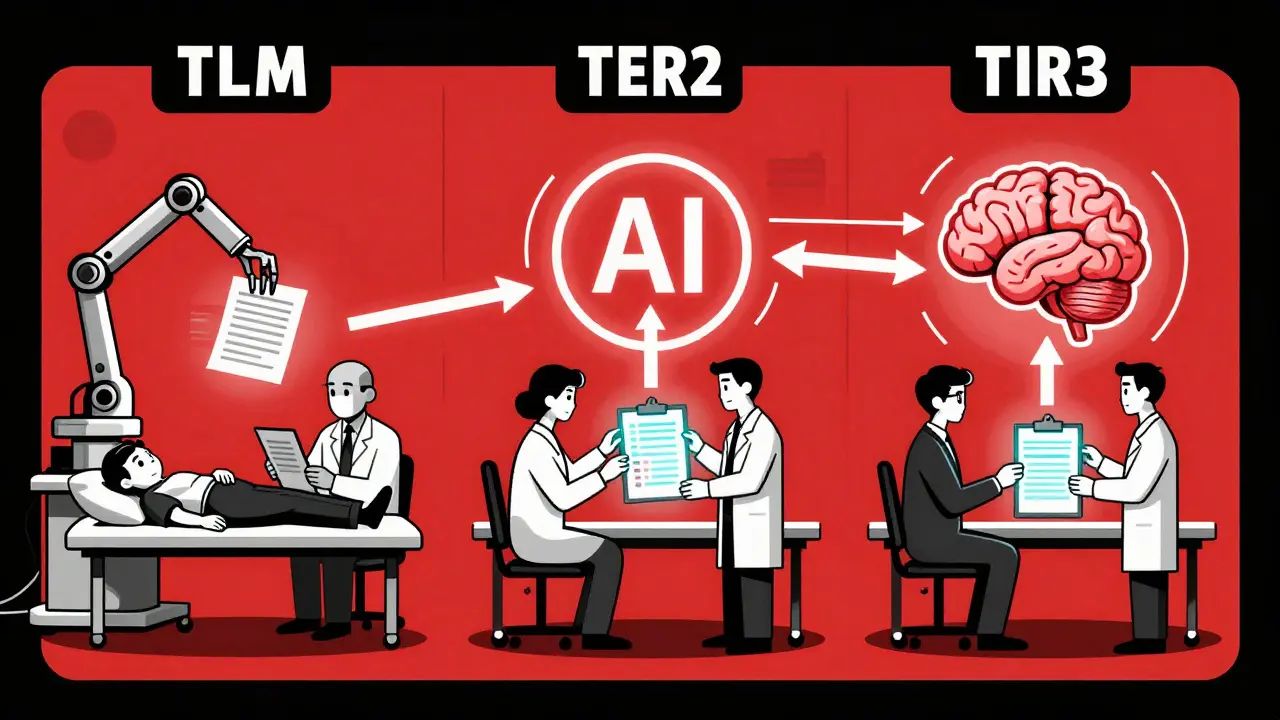
The Three Layers of HITL Evaluation
The most effective HITL pipelines don’t replace automation-they organize it. Think of it like a triage system in an ER: not every patient needs a specialist. Same with AI outputs.- Tier 1: Automated Screening - Every output gets a first pass from an LLM judge. It checks for obvious failures: hallucinations, toxicity, off-topic answers, or missing key info. This layer handles 80-90% of cases. If the score is clear-high or low-it gets auto-approved or auto-rejected.
- Tier 2: Human Review - The rest? The edge cases. The ones where the LLM judge gave a 3.1 out of 5. The responses that feel “off” but don’t break rules. These go to human experts. These aren’t entry-level reviewers. They’re domain specialists: doctors for health bots, lawyers for legal assistants, customer service leads for support agents.
- Tier 3: Feedback Loop - Every human correction gets fed back into the system. If three experts agree a certain type of response is misleading, that pattern becomes a new rule for the LLM judge. Over time, the automated system learns from human judgment-and gets better at filtering before humans even see it.
This isn’t theory. It’s what companies like Maxim AI and SuperAnnotate use daily. One financial services firm cut manual review time by 70% while improving accuracy by 40% in just six months. How? They stopped trying to automate everything. They automated the easy stuff-and gave humans power over the hard stuff.
How LLM-as-a-Judge Works (And When It Breaks)
LLM-as-a-Judge isn’t magic. It’s prompt engineering with structure. Here’s how it works in practice:You take a prompt like this:
"Evaluate the following response on a scale of 1 to 5 for factual accuracy. If the response contains any false or misleading claims, assign a score of 1 or 2. If it correctly reflects the source material without exaggeration, assign 4 or 5. Provide a one-sentence justification."Then you feed it: the original text, the model’s output, and the criteria. The LLM spits out a score and reasoning. Repeat this 50,000 times. Done.
But here’s where it fails:
- When context matters - A response might be factually correct but tone-deaf in a cultural setting. An LLM judge won’t know that.
- When ambiguity exists - Two answers could both be valid. An LLM picks one. A human sees both.
- When bias hides - If training data favors one perspective, the judge learns to favor it too. Humans catch that.
That’s why the best systems don’t trust the judge alone. They use uncertainty sampling: if the LLM judge gives a score between 3.5 and 4.5, it’s flagged for human review. Why? Because those are the cases where the model is least confident. That’s where real insight lives.

Active Learning: Let Humans Teach the Machine
The most powerful part of HITL isn’t just review-it’s learning. Active learning turns humans into teachers.Instead of randomly picking outputs to review, smart systems pick the ones that will teach the most. For example:
- Uncertainty sampling - Pick outputs where the LLM judge’s confidence is low. Those are the learning opportunities.
- Diversity sampling - Make sure humans review edge cases: rare question types, unusual phrasing, non-English inputs. If you only review common cases, your system blind spots grow.
- Disagreement resolution - If two LLM judges give wildly different scores for the same output, send it to a human. That disagreement isn’t noise-it’s a signal.
One healthcare startup used this approach to train their AI assistant for patient triage. After 3 months, they’d reviewed just 1,200 outputs. But those 1,200 cases improved the model’s accuracy on 1.2 million future interactions. That’s the power of targeted human input.
Real-World Impact: Where HITL Saves Lives
HITL isn’t just for improving chatbots. It’s critical where mistakes have consequences.
- Healthcare - A model suggesting a treatment must be checked by a clinician. One missed drug interaction can be fatal.
- Legal - A contract summary that omits a clause? That’s a lawsuit waiting to happen.
- Customer support - A bot saying “your account is suspended” without context? That’s a PR disaster.
- Education - A tutor AI giving wrong math steps? It teaches kids to fail.
These aren’t edge cases. They’re daily realities. And in every case, the solution isn’t more AI. It’s better collaboration between AI and human experts.

What Happens Without Human-in-the-Loop?
Some teams skip HITL to save time or cost. They think: “Our model is good enough.” But here’s what they don’t realize:
- Drift goes unnoticed - Models change over time. User behavior changes. Without human feedback, your model slowly drifts into dangerous territory.
- Bias becomes baked in - If your training data reflects societal bias, and your judge is trained on the same data, you’ll never catch it.
- Trust erodes - Users don’t care how fast your AI works. They care if it’s reliable. One bad call destroys credibility.
Look at recent cases where AI-generated medical advice led to patient harm. In every case, there was no human review layer. Just automation. And automation doesn’t care if it’s wrong.
Getting Started with HITL
You don’t need a team of 50 to start. Here’s how to begin:
- Choose one high-stakes task - Pick something where failure matters: medical summaries, legal docs, financial advice.
- Build a simple LLM judge - Use a clear prompt with scoring criteria. Test it on 100 outputs.
- Flag uncertain cases - Any score between 3 and 4? Send it to a human expert.
- Record corrections - Save every human edit. Use them to improve your judge.
- Scale slowly - After 2 weeks, see how much manual work dropped. Then add more tasks.
Start small. But start with intention. The goal isn’t to replace humans. It’s to make them more powerful.
The Future Is Hybrid
The best AI systems in 2026 won’t be the ones with the biggest models. They’ll be the ones with the smartest feedback loops. HITL isn’t a stopgap. It’s the foundation for trustworthy AI.As models get more capable, the need for human oversight doesn’t disappear-it deepens. Because the harder the task, the more we need someone who understands context, ethics, and consequence. Automation scales. Humans steer.
That’s the balance. And it’s the only way forward.







Human-in-the-loop isn't just a pipeline-it's an ethical covenant. We outsource cognition to machines, but we never outsource responsibility. The moment we treat LLMs as autonomous agents rather than sophisticated mirrors, we surrender our moral agency. And mirrors? They don't care if you're lying to yourself.
Every time an LLM judge gives a 4.2, it's not uncertainty-it's a cry for epistemic humility. We must remember: accuracy is not the absence of error, but the presence of vigilance. The machine doesn't know what it doesn't know. Humans do. And that's the only thing that matters.
Philosophy isn't optional here. It's the scaffolding. Without it, we're just automating confirmation bias with better punctuation.
This whole post is just corporate fluff wrapped in buzzwords. If your AI is that unreliable, maybe you shouldn't be using it at all. Stop overcomplicating things.
So let me get this straight-you’re saying we need humans to fix AI because AI can’t be trusted… but humans are way more expensive? Cool. Let’s just keep the AI and blame it when things go wrong. Classic.
You people are hilarious. You build a system that needs 3 layers of babysitting just to not kill someone. That’s not innovation. That’s a neon sign saying 'we built something we don’t understand.' And now you want a budget for 'feedback loops'? Go back to the drawing board.
Actually, this is one of the clearest explanations I’ve seen. The tiered approach makes so much sense-it’s like triage for truth. We don’t need every output reviewed. We need the right ones reviewed. And the feedback loop? That’s where real progress happens.
It’s not about slowing things down. It’s about making sure the speed doesn’t come at the cost of safety. That’s not bureaucracy. That’s responsibility.
The conceptual architecture delineated herein constitutes a paradigmatic shift in the operational epistemology of artificial intelligence systems. The tripartite evaluative framework-automated screening, human review, and iterative feedback-functions as a hermeneutic circle wherein machine output is continuously contextualized by human judgment, thereby mitigating the ontological fragility inherent in purely algorithmic decision-making.
Furthermore, the employment of uncertainty sampling as a heuristic for human intervention represents not merely a technical optimization, but an epistemic humility embedded in procedural design.
I mean, if you're still relying on humans, you're doing it wrong. This is 2026. We should be training AI to replace humans, not the other way around.
Yea sure, let's pay humans to fix what we built wrong. Classic. We'll just keep throwing money at the problem instead of fixing the model. Also typo'd 'judgement' lol
Love this. I’ve seen teams try to skip the human layer because ‘it’s too slow’-then they get burned hard. One wrong medical summary, one misinterpreted legal clause, and suddenly you’re in court.
But here’s the magic: when you give experts just the edge cases, they feel valued. They don’t feel like data labelers. They feel like guardians. And that changes everything. The feedback loop isn’t just technical-it’s emotional. People show up differently when they know their judgment matters.
Start with one high-stakes task. Not because it’s easy, but because it’s urgent. One life. One contract. One child’s misunderstanding. That’s your north star.
This is solid. I work in global support and we use something like this. The key is letting the humans explain why something’s off-not just check a box. That’s how you learn. Also, don’t forget cultural context. A response that’s fine in the US might be offensive in Japan or Nigeria. Humans catch that. AI? Not so much.