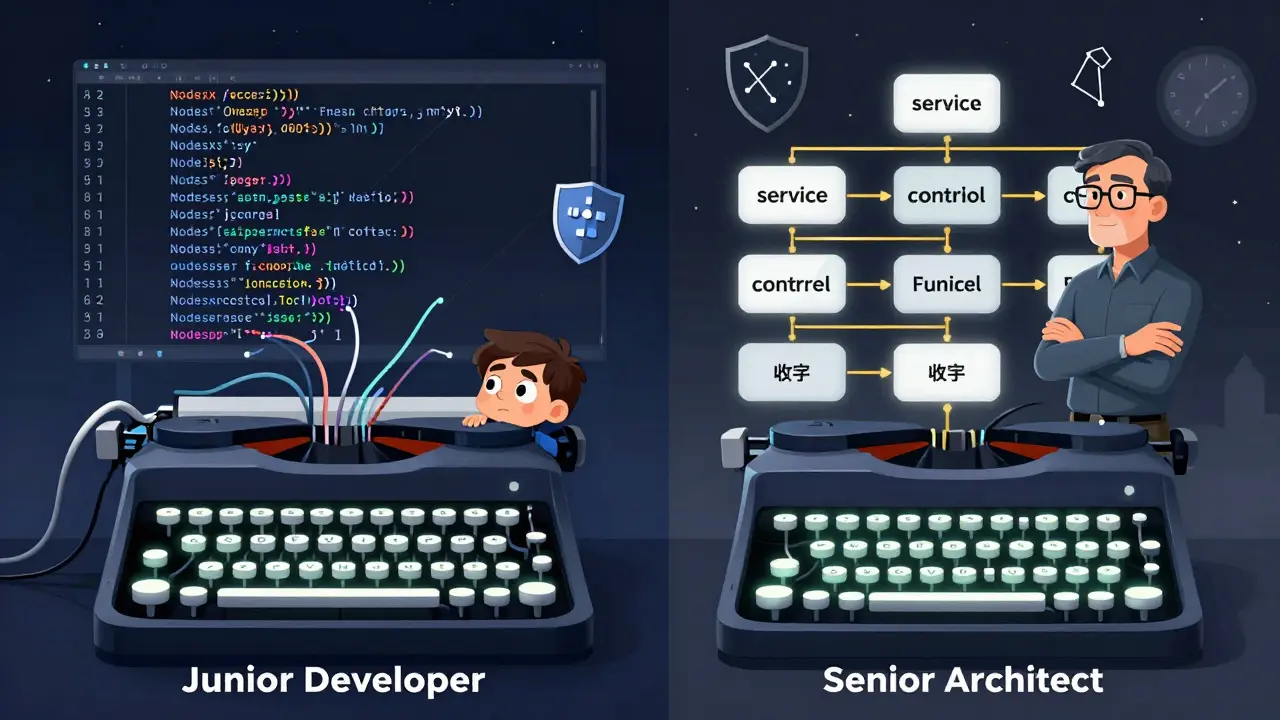
Role Assignment in Vibe Coding: How Senior Architect and Junior Developer Prompts Change Code Output
Role assignment in vibe coding transforms AI code generation by specifying whether the AI should act as a senior architect or junior developer. Senior prompts deliver secure, production-ready code with better architecture, while junior prompts excel at teaching fundamentals. This technique cuts review time by up to 40% and is now used by 68% of professional developers.

Life Sciences Research with Generative AI: Protein Design and Literature Reviews
Generative AI is revolutionizing life sciences by designing custom proteins from scratch and transforming how researchers review scientific literature. This technology enables function-first engineering of proteins that never existed in nature, accelerating drug discovery and gene therapy development.

Content Moderation Laws and Generative AI: Platform Duties and Safe Harbors
As of 2026, platforms face strict laws on AI-generated content. From EU rules to U.S. deepfake bans, they must label, detect, and remove harmful synthetic media-while balancing safety and free expression.

Threat Modeling for Large Language Model Integrations in Enterprise Apps
Threat modeling for LLM integrations in enterprise apps is no longer optional. Learn the top five real-world risks-prompt injection, data poisoning, model theft, supply chain flaws, and insecure outputs-and how tools like AWS Threat Designer are making security practical for development teams.

Database Schema Design with AI: Validating Models and Migrations
AI is transforming database schema design by generating production-ready models from plain language, validating structures for integrity, and auto-generating safe migrations. Learn how it works and why human oversight still matters.

How Autoregressive Generation Works in Large Language Models: Step-by-Step Token Production
Autoregressive generation powers major LLMs like GPT-4 and Claude by predicting text one token at a time. Learn how this step-by-step process works, why it’s dominant, and its key limitations.

Building AI Chatbots and Assistants with Vibe Coding and Retrieval Systems
Learn how vibe coding and retrieval systems let anyone build AI chatbots without writing code - and why security, debugging, and enterprise readiness still require human oversight.

On-Prem vs Cloud: Enterprise Trade-Offs and Controls for Modern Coding
Choosing between on-prem and cloud for enterprise coding isn't about trends-it's about control, cost, and compliance. Learn the real trade-offs that affect deployment speed, security, and long-term scalability.

Next-Generation Generative AI Hardware: Accelerators, Memory, and Networking in 2026
In 2026, generative AI runs on next-gen accelerators, HBM4 memory, and Ethernet-based networking. NVIDIA, AMD, Microsoft, and Qualcomm are all pushing new silicon that’s reshaping how AI models train and infer.

Self-Supervised Learning in NLP: How Large Language Models Learn Without Labels
Self-supervised learning lets AI models learn language by predicting missing words in text - no human labels needed. This technique powers GPT, BERT, and all modern large language models.

Design-to-Code Pipelines: Turning Figma Mockups into Frontend with v0
v0 transforms Figma mockups into production-ready React code with Tailwind CSS, cutting design-to-dev handoff time by up to 40%. Learn how AI-powered pipelines work, what to prepare, and how teams are shipping faster in 2026.

Vendor Management for Generative AI: SLAs, Security Reviews, and Exit Plans
Generative AI vendor management requires tailored SLAs, deep security reviews, and clear exit plans to avoid bias, data leaks, and operational disruption. Here's how to build a resilient framework.
